![[Un]Churned by Gainsight](https://substackcdn.com/image/fetch/$s_!7AoO!,w_120,h_120,c_fill,f_webp,q_auto:good,fl_progressive:steep/https%3A%2F%2Fsubstack-post-media.s3.amazonaws.com%2Fpublic%2Fimages%2Ffe2167ac-0bcf-4575-9712-8d5ef3588851_300x300.png)
![[Un]Churned by Gainsight](https://substackcdn.com/image/fetch/$s_!hKlf!,e_trim:10:white/e_trim:10:transparent/h_72,c_limit,f_auto,q_auto:good,fl_progressive:steep/https%3A%2F%2Fsubstack-post-media.s3.amazonaws.com%2Fpublic%2Fimages%2Fe14b36dd-52b9-48a3-9f93-3f6a459d55ff_1344x256.png)
From D&D to Customer Success: What Context Engineering Actually Unlocks
The AI skill that matters most right now has nothing to do with prompts.
![[Un]Churned's avatar](https://substackcdn.com/image/fetch/$s_!vkJ0!,w_108,h_108,c_fill,f_webp,q_auto:good,fl_progressive:steep/https%3A%2F%2Fsubstack-post-media.s3.amazonaws.com%2Fpublic%2Fimages%2F0464ad30-26c2-4f32-b429-ae4283dd5586_200x200.png)

It was 11 pm in my hotel room in Austin. I had a sales kickoff presentation to give in the morning, and probably should’ve been sleeping. Instead, I was in the middle of a boss battle.
Rama the Bard, my level 14 dwarf, needed help. I had my Granola transcripts pulled up, my character sheet open, and Claude running in the background helping me track the session and figure out my next move.

Here’s why I’m telling you this: the reason it works... tracking a D&D campaign in Claude, the same tool I use to prep for customer meetings, draft product specs, and manage my inbox... is because the underlying capability is the same across all of it. You give the model what it needs to know. It thinks. It helps. The use case is almost irrelevant.
That insight, obvious as it sounds, took a year and a half of playing with my AI setup to fully internalize. And it’s the thing I think most CS leaders are still missing.
Level Up Your Context, Not Your Prompts
I’ve been using Claude as my daily driver since July 2024. It just felt like it got me both better and quicker. Then last fall I moved from the Claude Desktop app into Claude Code, and it was like casting Knock to unlock the door to true personalization with my AI setup.
Early on, like everyone, I spent a lot of time obsessing over prompts. The right phrasing, the right structure, the right level of specificity. Prompt engineering felt like a skill worth developing, and for a while it was.
That’s less true now. The models have gotten good enough that a well-formed question is table stakes. The newest term on the block is context engineering, and it’s the most useful reframe I’ve found.
Context engineering is about what you give the model to think with. The transcripts. The account history. The relationship signals. Your customer’s stated goals from the last three QBRs. Your own notes from a conversation six months ago that you’ve half-forgotten. The model can reason over all of that, but only if it’s there in the first place.
And Customer Success (CS) might be the most context-heavy job in any company. Every interaction requires synthesizing account history, relationship dynamics, product usage data, business goals, recent sentiment. The problem? Most of that context lives across five different tools and a CSM’s own memory. Context engineering is the discipline of getting that information in front of the model systematically, rather than hoping you remember the right detail at the right moment.
The people developing that instinct now, while everyone else is still copy-pasting one transcript at a time, are quietly building a compounding advantage. That gap is growing faster than most CS leaders realize.
Side Quest: The Insurance Save
Let me step outside of work for a second, because I think a personal example makes this click faster.
My home insurance had been creeping up for two years. I kept meaning to shop around. Never did. Finally, one evening, I loaded my policy documents into Claude and asked it to help me research local competitors. When quotes came back, I dropped them into a new chat and asked Claude to figure out which was genuinely better, where I had room to negotiate with my existing agent, and even draft and send emails to four different companies with the info they needed to quote me.
I’m saving $1,200 a year now.
Claude didn’t do anything a smart assistant couldn’t do. What made it work was that it had everything it needed. The policy. The numbers. The full picture. It could reason about my situation instead of a generic version of it.
That’s the whole concept. Give the model your actual context, and the output goes from generic to genuinely useful. The quality of the input determines the quality of the thinking.
It works the same way in CS.
What This Actually Looks Like
CS teams sit on some of the richest contextual data in any company. Call recordings, health scores, renewal signals, stakeholder history, communication patterns. And most of that data is either locked in a platform no one has time to open or scattered across tools that don’t talk to each other.
Here’s what my mornings look like now. I run my meeting prep every day off my Gainsight and Staircase AI MCP connections. Account data, calendar, relationship signals, all accessible to Claude at once. I type something like “prep me for my meeting with TigerConnect” and get a structured brief back before I’ve finished my coffee. Health scores, open risks, stakeholder context, recent communication sentiment, feature requests they’ve raised. Everything comes back at once rather than one piece at a time.
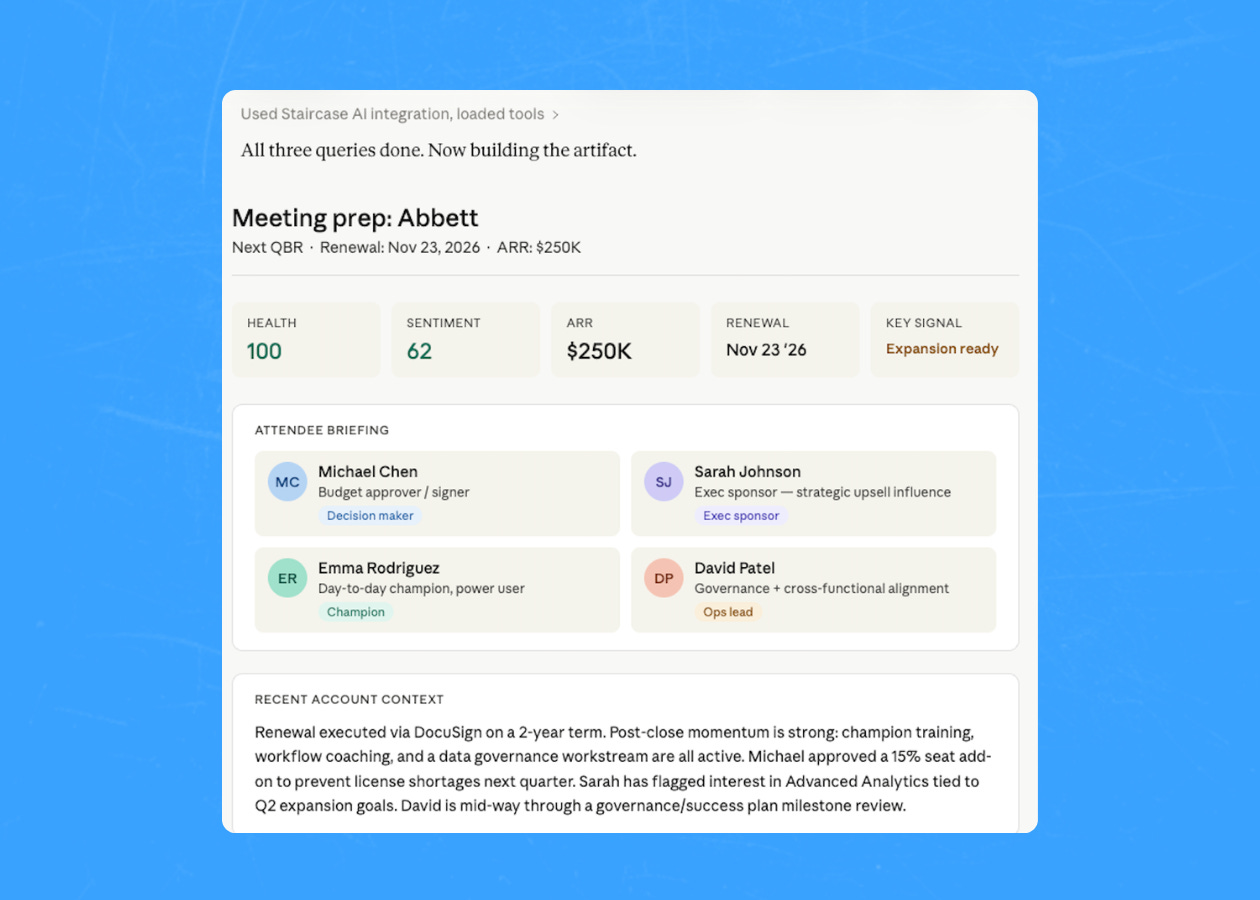
I walk into every customer call that day genuinely prepared. Not “I skimmed the account page for two minutes” prepared. “I know what’s happening in this relationship and what to pay attention to” prepared. That used to take 30 minutes of tab-switching per meeting. For a full day of calls, the compound effect is massive.
And meeting prep is just the most obvious example to craft a skill around. The same principle applies to renewal planning, QBR prep, escalation triage, onboarding handoffs. I worked with several teammates to outline 19 workflow use cases that show what’s possible when your AI tools have real customer context to work with. We keep adding more. The pattern is always the same: give the model what it needs, and the output is worth acting on.
The Skill Tree Most CSMs Are Ignoring
The most practical thing I’ve built into my workflow is also the simplest. And it came from one question I started asking myself after every task:
Is this something I’ll need to do again?
If yes, I tell Claude to make a skill. A reusable approach that encodes what good looks like for that specific type of work. Meeting prep. Account briefings. Renewal summaries. Each one gets faster and more accurate over time because the model already knows how I want to work.

I’ve seen this coming over the past two years, and its truer than ever now: English is becoming a kind of programming language. When you ask Claude to save a workflow as a skill, you (and Claude) are writing reusable logic in plain language. No code. Just clarity about what you want and why.
Try it. Next time you finish refining a workflow with Claude and the output is exactly right, say this:
“I want you to review the process we just went through and help me turn it into a skill file that we can use next time we run this.”
That one sentence turns a conversation into a reusable tool. It costs you nothing to try. And once you have two or three of these, something shifts. You stop thinking about AI as a thing you “use” and start thinking about it as a system you’re building. Your own system. One that gets smarter every time you work with it.
CS teams have always had a knowledge transfer problem. The CSM who leaves takes their playbook with them because the real account context lives in their head. Skills are a way to start externalizing that institutional knowledge so it compounds with the team rather than walking out the door.
The Conversation That Changed My Perspective
About six weeks ago, I demoed one of these workflows to Diane Wu, a CS leader at Google Cloud. At the end of the call, she asked for a follow-up meeting. Not about the product. Not about pricing. She wanted to talk about what CSMs need to start doing and learning now, because she could see the role changing.
She wasn’t alarmed. She was paying attention.
We ended up recording an episode of the [Un]Churned podcast together about a month later, and one thing she said hasn’t left me: “Leaders need to be thinking as far out ahead as possible right now, because these timelines are accelerating faster than anyone expected. This isn’t a future conceptual thing. It’s happening now.”
Nobody has the playbook for this yet. But the teams that get comfortable with that uncertainty the fastest... the ones building loops, encoding knowledge, and letting the model teach them how to use it rather than waiting for someone to hand them a manual... those are the teams that will be writing the thought leadership two years from now instead of reading it.
Your Turn to Roll the Dice
If you want a starting point, here’s the one I give everyone:
Pick one task you do repeatedly. Do it with Claude (or another LLM, if you have to). Refine the output until it’s exactly what you wanted. Then ask Claude to save that approach as a reusable skill.
That’s it. One task, done well, encoded. Then do it again with the next one.
The momentum builds faster than you’d expect. You go from “I use AI sometimes” to “I have a system” in a matter of weeks. And once that shift happens, it’s hard to go back.
My goal when I shared all of this with our go-to-market team recently was simple. By Thanksgiving, I want them sitting at dinner, trying to explain what they’ve been building with AI, only to get blank stares from their family. Not because they’ve gone off the deep end, but because they’re operating at a level that’s genuinely hard to describe from the outside. It’s like having a psychedelic experience and trying to explain it to your mom. Some things you just have to experience yourself.
Oh, and... if you don’t know where to start, ask Claude. It’ll show you.
This is Part 1 of a two-part series on context engineering. Next up: what it looks like when you go deeper. Building persistent systems, architecting reusable workflows at scale, and why the people treating AI as infrastructure are pulling away from everyone else.
Brady Bluhm is a Senior Product Manager at Gainsight, where he leads Staircase AI. Before tech, he spent a decade as a professional actor (you might know him as Christopher Robin in Disney’s Winnie the Pooh). He pivoted through sales, CS, and enablement before landing in product, where he founded AI4All at Gainsight and taught 50+ teamm,ates AI fluency from scratch. He builds with AI every day and recently spoke with [Un]Churned about how CS teams can build AI fluency before their customers do.

 | A guest post by
|
Why put the any burden on the CS team?
Context recovery, analysis, and correlation is 100% handsfree.
No data collection, no customer artifact hunting at the data source, no transcripts, to upload into Claude or any tool.
HandoffIQ.ai does this automatically.
Customer Context is mapped into GS automatically.
Done.
See you at Pulse.