![[Un]Churned by Gainsight](https://substackcdn.com/image/fetch/$s_!7AoO!,w_120,h_120,c_fill,f_webp,q_auto:good,fl_progressive:steep/https%3A%2F%2Fsubstack-post-media.s3.amazonaws.com%2Fpublic%2Fimages%2Ffe2167ac-0bcf-4575-9712-8d5ef3588851_300x300.png)
![[Un]Churned by Gainsight](https://substackcdn.com/image/fetch/$s_!hKlf!,e_trim:10:white/e_trim:10:transparent/h_72,c_limit,f_auto,q_auto:good,fl_progressive:steep/https%3A%2F%2Fsubstack-post-media.s3.amazonaws.com%2Fpublic%2Fimages%2Fe14b36dd-52b9-48a3-9f93-3f6a459d55ff_1344x256.png)
We Built an AI Agent in Two Weeks. Here’s What It Exposed.
What actually broke once the code for our Instance Review agent ran.
![[Un]Churned's avatar](https://substackcdn.com/image/fetch/$s_!vkJ0!,w_108,h_108,c_fill,f_webp,q_auto:good,fl_progressive:steep/https%3A%2F%2Fsubstack-post-media.s3.amazonaws.com%2Fpublic%2Fimages%2F0464ad30-26c2-4f32-b429-ae4283dd5586_200x200.png)

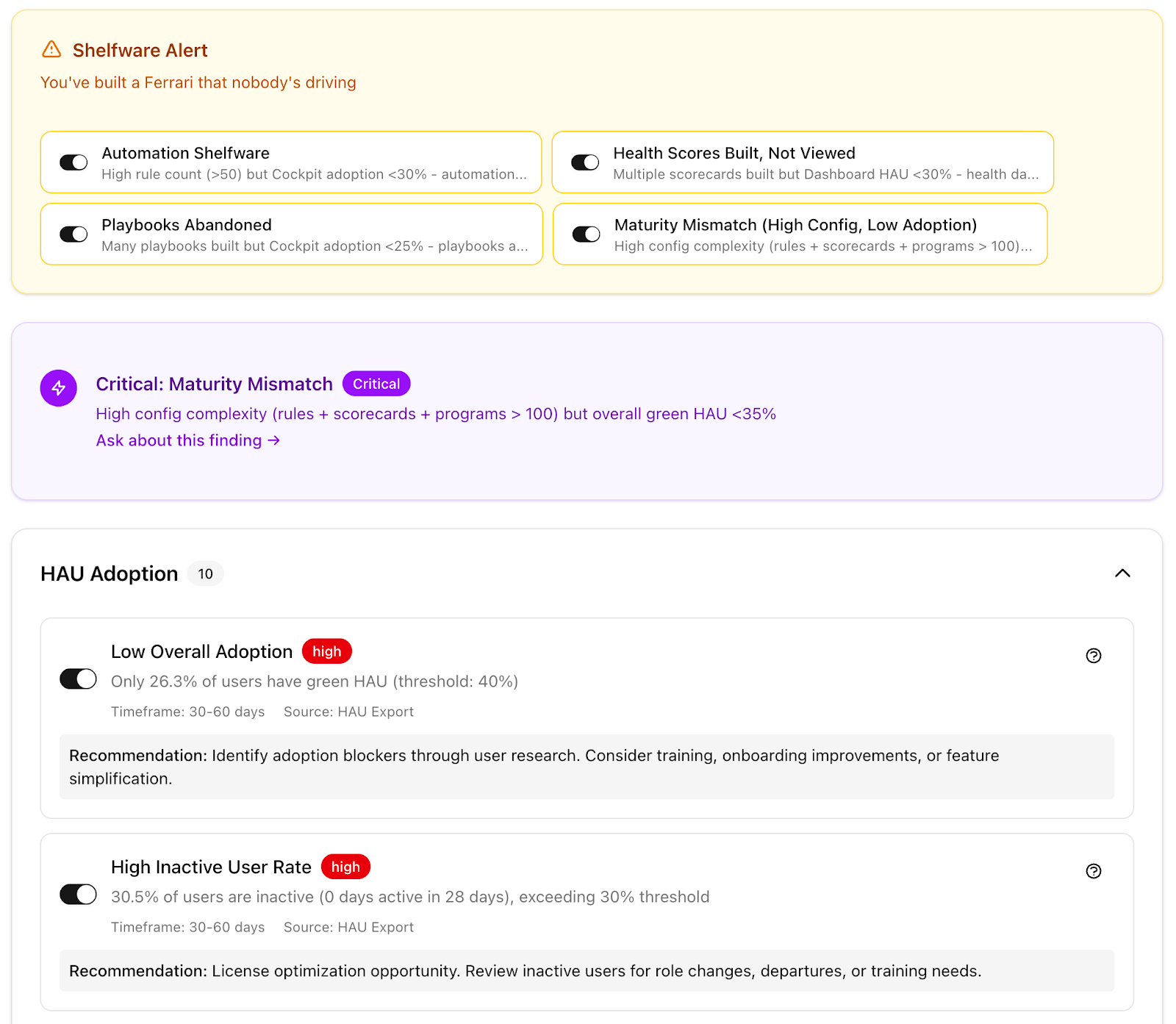
In Part 1: We Thought We Knew Our Own CS Process. A Week of Discovery Proved Us Wrong, I shared how working with Method Garage helped us find gaps in our Instance Review (IR) process.
IRs are one of the most important activities a CSM can do, but also one of the most time-consuming. With so much room for improvement, it was an ideal starting place for us to apply an AI-powered solution. In just one week, we picked apart the current IR process through a rapid yet thorough discovery process. Here’s a quick recap of our findings:
IRs involve two completely different activities: technical analysis and value narrative.
We had an internal expert, Principal CSM Elliot Hulverson, who in his 8 years at Gainsight had found a way to make IRs fast and effective. He was our go-to resource for building an efficient solution.
We had 80%-90% of the data we needed between an existing config export and usage data from our Gainsight PX integration.
Our purpose shifted from accelerating the IR process, to enabling CSMs to take on this laborious task that was effectively non-existent.
We brought in Method Garage to run a Blueprint Sprint. One week to map the current state. Two weeks to build a working prototype.
Here’s what happened when we turned code into reality, and the biggest lessons came when the system started failing.
What We Actually Built
After compiling the findings from our discovery process, we started the process of crafting an agentic Instance Review.
The prototype could take a customer’s Gainsight setup and create a clear review in a dashboard, similar to how humans do it today. But could we take a motion that normally takes 8-12 hours of effort and reduce the work without compromising judgment?
Instance Reviews aren’t a new concept and the goal wasn’t to just build a clever internal service. We needed to understand whether the review itself can be meaningfully “agentified” without losing credibility with customers.
We also wanted to create this solution using reusable building blocks, rather than a fixed workflow. Our objective is to eventually use this same engine to support QBR prep, risk response, and health monitoring without having to rebuild logic each time. So we opted to break the work into smaller pieces.
In our discovery process, we had identified the two activities that made up IRs: technical analysis and value narrative. So, we split the review process into two distinct capabilities that aligned with these activities:
Config Intelligence parses a customer’s Gainsight configuration export (a 25-megabyte Excel file spanning 14 structured tabs) and evaluates it for structural signals like:
Stale scorecards
Journey Orchestrator programs that are limited to email sends
Playbooks that exist but never fire
Rules that have not triggered in over a year
Value Narrative, which takes those technical findings and translates them into business consequences. For example, if Config Intelligence detects a stale scorecard, Value Narrative surfaces the risks that issue poses. In this case, a stale scorecard could lead to a CSM missing warning signs.
Together, these capabilities allowed the system to generate an end-to-end Instance Review deck that looked familiar to a CSM, but was produced in seconds rather than hours. And since each of these capabilities provided a standalone workflow, not only were we tackling IRs, we set ourselves ahead for future projects.
The Big Test
Once the prototype worked, we tested it on data from our own instance and compared its results to a human-written Instance Review. This gave us a direct, side-by-side comparison.
The AI found many of the same issues as humans, such as:
Low dashboard use
Underutilized Success Plans
Limited Journey Orchestrator engagement
Unused reports
Outdated scorecards
It then created a review deck in seconds that would have taken much longer to build by hand. Most importantly, it brought consistency: the same data always led to the same findings, eliminating differences caused by manual review.

The overall match rate compared to human-led IRs landed around 60–70%, which turned out to be a clear win. CSMs weren’t starting from zero anymore and could focus on applying judgment rather than assembling slides.
What the AI Couldn’t See
We weren’t at 100% parity yet, but this was an opportunity to improve and learn more about the areas where results overlapped.
Here’s what we discovered:
The AI could not recognize strengths. It only pointed out problems and couldn’t say, “This is working, don’t break it,” as human reviewers often do. This gap matters because it shapes the conversation itself. A review that focuses on problems can derail what should be a constructive discussion. So, we have already started adding strength checks to ensure our reviews are balanced.
The AI’s strategic recommendations were also shallow. Its suggested approaches were broad, like “consider training.” Meanwhile, a human could suggest a deeper approach, such as establishing cross-functional ownership for digital work or tying health scores to measurable results. These suggestions were on the right track, but not very useful in practice. This simply means we need to keep massaging and fine-tuning our prompts and n-shot examples.
Even more telling were the gaps we didn’t expect. Both of our human reviewers identified unused AI features (i.e., Copilot, AI Takeaways, and AI Follow-Up) as clear opportunities, but the prototype missed them because those details were not included in the export. This wasn’t a problem with the model, but a limitation of the data: you can’t derive insights from information you don’t have.
Going Back to the Drawing Board
One particular discrepancy ultimately reshaped the prototype’s design. Both human reviewers said the customer’s usage of Gainsight’s Timeline feature was healthy and high, but the AI marked it as underused at 16.9% adoption, which was below its set threshold.
At first, it looked like the same data led to different conclusions. But when we looked closer, we realized the data wasn’t actually the same at all.
The problem was context. The AI couldn’t see what CSMs know from regular customer conversations or the details that affect how features are used. Maybe the customer isn’t using a particular feature due to security policies or other company constraints. Or perhaps the CSM is using relative judgment based on the company’s usage of other features. Meanwhile, the AI is using a strict rule.
This showed that our system was missing key information that only lives in a CSM’s head. It’s an important reminder that keeping humans involved is part of the design, not a limitation.
When the Users Pushed Back
We demoed the prototype to a group of CSMs and ops leaders who would actually be using it and received immediate (and humbling) feedback.
One CSM looked at the output and said, “An exec would look at this and say ‘so what?’ We have to translate these findings into the why.”
She was right. We built a strong tool for CS ops, with deep diagnostics, precise metrics, and detailed recommendations, but we missed that this is not what executives need. A VP of Customer Success doesn’t want that level of detail. They want the story. What does this mean for my business? What should I prioritize? What’s the impact?
The group made the division of work clear by letting the AI handle detailed analysis while humans added judgment, context, and storytelling.
What the Prototype Revealed Beyond the Plan
The feedback sessions revealed what we had misunderstood, helping de-risk the decision to move forward.
We proved we could parse complex exports, apply human-like rules, and generate coherent output. These assumptions became facts only after the system was tested on real data.
We also found problems that planning alone would not have revealed, such as missing AI feature adoption in exports, viewer licenses that make usage numbers look higher, and thresholds based on outdated documentation. These are real, common issues, and investing in production without learning this would have been a risky guess.
If you take away anything from this article: don’t rush straight to production. We could have spent months refining requirements for a production build and still missed the Timeline problem, the export gaps, and the “so what?” feedback. The prototype surfaced all of that in three weeks.
The Lessons That Stuck
1. Speed is how learning happens.
We spent one week understanding the problem and two weeks building, so by week three, we had something real people could critique. Method Garage helped us move fast, and that tempo mattered. If we had spent months refining requirements or debating architecture, we’d still be arguing over schemas rather than learning from real output.
2. “Human-in-the-loop” as a key feature.
CSMs have customer knowledge and context that an Excel sheet can’t replicate. There’s so much push in the AI industry to do everything and take action. But AI plus humans is where the real magic happens. Humans aren’t just there to do final review before sending. They’re part of the intelligence and intentionally part of the AI-enabled workflow.
3. You don’t get the design right without your users in the room.
The demo session with CSMs and ops leaders was more productive than any planning meeting we could have run, because people were reacting to something tangible. They could see what worked, what didn’t, and how to improve it.
4. Prototypes reduce risk by exposing failure.
Even when it wasn’t polished, the prototype showed what was possible and what wasn’t, helping us decide how to move forward. That’s why prototyping isn’t just a phase before the real work. It is the work, and often the only way to find out which assumptions deserve to survive.
What’s Next
At 60–70% match with human reviews, the prototype gave us what we needed: clarity on what’s worth automating and what still needs a human.
Now we’re fixing what we found. CSMs are rewriting thresholds based on how they actually evaluate usage so we can fix the Timeline misdiagnosis. We’re building two separate outputs to solve the “so what” problem: detailed diagnostics for CS Ops and business narratives for CS Execs.
This is the reward for doing discovery well. You build a system that keeps getting smarter as you use it for new problems.
Part 1 was about learning before building. Part 2 was about what we learned once we started building and left the safety net behind.
Both matter. Neither is optional.

Method Garage played a huge role in getting this off the ground. Their strength is translating messy, human workflows into something structured enough to build against. They surface the knowledge most teams skip and force the hard decisions early. If you’re applying AI to complex, judgment-heavy processes, that kind of rigor matters.
If you’re experimenting with AI within Customer Success, especially in agentic, workflow-heavy environments, I want to hear what’s actually holding up under pressure. Drop a comment or reach out directly.
 | A guest post by
|