![[Un]Churned by Gainsight](https://substackcdn.com/image/fetch/$s_!7AoO!,w_120,h_120,c_fill,f_webp,q_auto:good,fl_progressive:steep/https%3A%2F%2Fsubstack-post-media.s3.amazonaws.com%2Fpublic%2Fimages%2Ffe2167ac-0bcf-4575-9712-8d5ef3588851_300x300.png)
![[Un]Churned by Gainsight](https://substackcdn.com/image/fetch/$s_!hKlf!,e_trim:10:white/e_trim:10:transparent/h_72,c_limit,f_auto,q_auto:good,fl_progressive:steep/https%3A%2F%2Fsubstack-post-media.s3.amazonaws.com%2Fpublic%2Fimages%2Fe14b36dd-52b9-48a3-9f93-3f6a459d55ff_1344x256.png)
Before the Agent Ships: The Human Layer Behind Gainsight's Agent Evaluation Process
A behind-the-build look at what it actually takes to evaluate an AI agent for customer conversations
![[Un]Churned's avatar](https://substackcdn.com/image/fetch/$s_!vkJ0!,w_108,h_108,c_fill,f_webp,q_auto:good,fl_progressive:steep/https%3A%2F%2Fsubstack-post-media.s3.amazonaws.com%2Fpublic%2Fimages%2F0464ad30-26c2-4f32-b429-ae4283dd5586_200x200.png)

Before an AI agent ever reaches a customer, someone has to teach it what “good” actually sounds like. Not “good” as in grammatically correct. In the case of Gainsight’s Renewal Agent, “good” means the customer on that call decides whether the relationship is worth continuing.
When Sergey Kondratiuk, Principal Engineer at Gainsight and co-founder of Update AI (now Gainsight Atlas), set out to build the evaluation system behind what would become the Gainsight Atlas Renewal Agent, he knew the engineering side was solvable. The harder problem was the criteria.
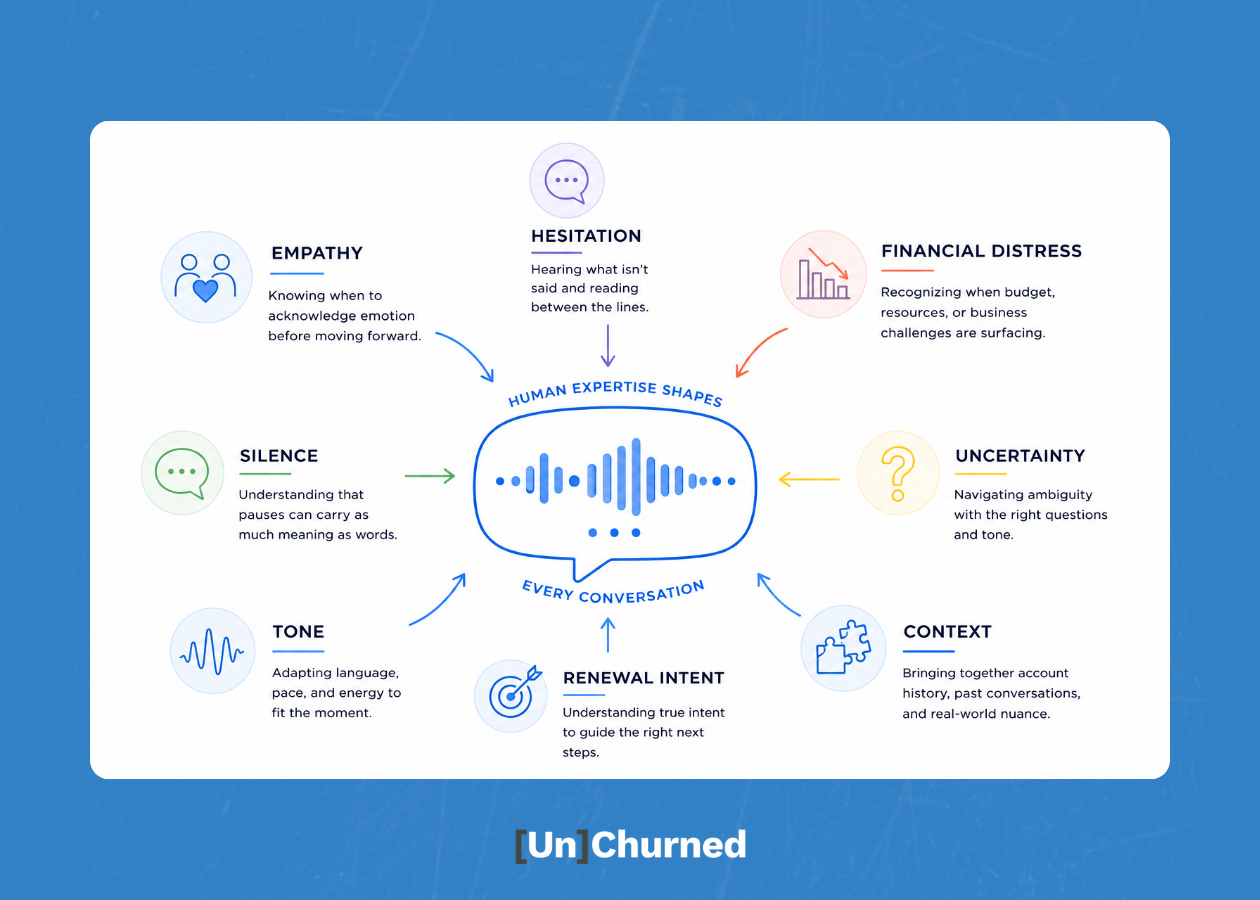
What does the appropriate tone sound like in a conversation where a customer is telling you their business is struggling? How do you define the right way to handle a customer who hints at churn three times before the consent recording even kicks in? Those aren’t questions with clean algorithmic answers. They come from years of being on calls. So, Sergey brought in someone who had that expertise. That’s where Skye Maddox, Senior Enterprise CSM at Envoy and contracted CS annotator for Gainsight, came into the picture.
What followed was a crash course in what it actually takes to teach an AI agent to read a room.
The Edge Cases Only a Human Can Surface
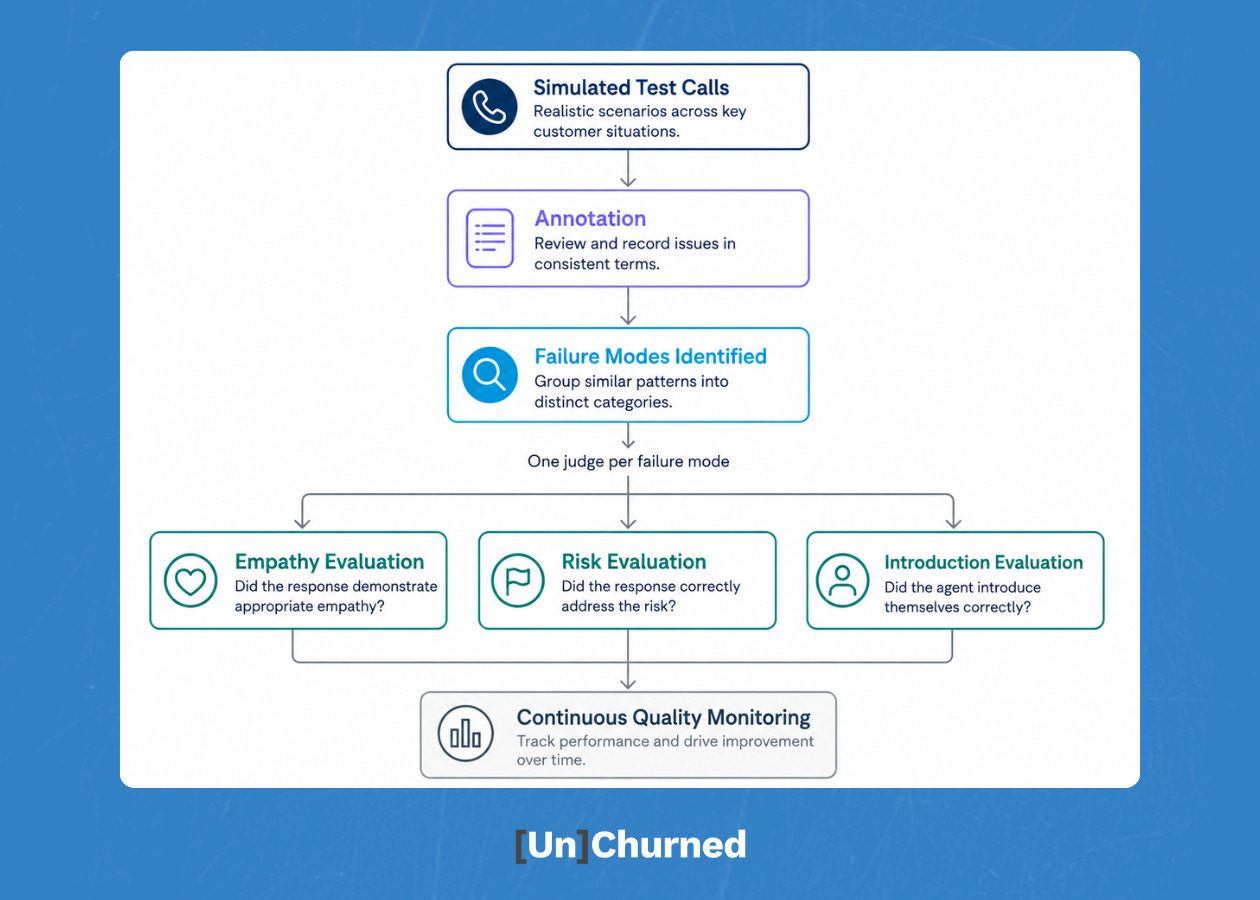
The first phase was stress testing. This consisted of running hundreds of simulated calls with the renewal agent and deliberately surfacing every edge case Skye had encountered in real customer conversations. The customer who opened the call by saying they can’t afford to renew, then gets asked two minutes later whether they plan to renew. The customer who switched languages mid-call. The customer who went quiet in a way that any experienced CSM would read as “I’m about to churn,” but that the agent has no vocabulary for yet.
“If there’s a voice agent handling renewals,” Skye says, “it’s going to be new to a lot of people. The very first interaction they have with it matters. Because there’s so much skepticism about AI already.”
Skye’s recent experience with AI had stuck with her. She’d called into Dominos and encountered an AI voice agent. The experience was so bad, she immediately asked for a human. The stakes of a renewal conversation are objectively higher (a fumbled call doesn’t just mean a wrong topping, it means a lost account) but the instinct she took from that moment stayed with her through every test call she placed. Her benchmark wasn’t “did the agent complete the task.” It was “would I want to keep talking to this thing.”
From Stress Test to System: How Annotation Works
Stress testing alone doesn’t improve an agent. What turns test calls into a learning system is annotation.
Here’s how the process works: after each test call, Skye logged what went wrong. Not in engineering terms, but in CSM terms. The agent ended a call without a proper close. It switched languages mid-conversation without acknowledging the shift. It misread a polite hedge as a soft yes. Those observations were compiled, fed into AI to identify patterns, and grouped into distinct failure modes categorizing what could go wrong in a renewal conversation.
Those failure modes became the foundation for what Sergey’s team built next: judges. A judge is a structured LLM call that runs alongside the agent and evaluates every conversation against a single, specific criterion. One judge evaluates whether the agent acknowledged a customer’s financial distress before moving to the renewal question. Another evaluates whether the call summary correctly flagged churn risk. Another checks whether the agent introduced itself appropriately. The reason judges are scoped that tightly is accuracy. The narrower the task, the more precise the evaluation.
But judges are only as good as the criteria they’re built around; and that criteria came from Skye. A true subject matter expert is critical at this stage. Engineers can do their best to anticipate failure modes, but without the experience of someone in those shoes everyday, they’re likely to miss what an SME can see coming.
The Calls Nobody Scripted For
Skye’s input wasn’t a QA step or a sanity check at the end. Her CS pattern recognition was the raw material the entire eval system was built from. Without it, there would have been nothing to build judges around.
Two failure modes in particular capture what only CS experience could have surfaced:
Identifying Churn Intent
Customers don’t say “I’m going to churn.” They hedge. They deflect. They say things like “we’d need to look at this internally” or “we’re going through some changes.” A CSM hears those phrases and adjusts. Skye tested this extensively and identified different inflections, levels of uncertainty, and ways of expressing the same hesitation, to see whether the agent would read it correctly in its call summary.
“You want to make sure you’re capturing renewal intent correctly,” she says. “Because you could put a renewal manager in a weird spot if the agent says they’re likely to renew and then they call and the customer says, no, actually, I said I was undecided.”
A situation like this is far beyond a minor inconvenience. If the agent is supposed to save CSM time by handling initial renewal outreach in long-tail segments, and it’s misclassifying intent, it’s creating rework and eroding trust in the system at exactly the moment when the relationship is most fragile.
The Consent-Recording Gap
The consent-recording gap surfaced the same kind of problem. While the agent’s behavior was technically correct, it was humanly wrong. In one test call, the agent designed a sequence—introduce, collect consent, then engage—which is by the book from a compliance standpoint. But real conversations don’t wait for the right moment to get emotionally complicated.
A customer who says something important before the formal start of the call is still saying it. A CSM would know to hold that. The agent didn’t. For example, a simulated customer opened with “my business isn’t doing well and I’m not sure I can afford this renewal”, but a few minutes later, would get a bright, undaunted “so, are you thinking about renewing your subscription?”
“I knew that would tick someone off,” Skye says. “Because I know it would’ve ticked me off.”
These are the gaps that close when engineering and CS are working together from the start.
The Feedback Loop Doesn’t Have a Finish Line
The eval system doesn’t just catch problems before launch. It keeps watching after the agent goes live. Manually reviewing every conversation at scale is a gargantuan feat. But judges and metrics make that ongoing monitoring possible. How often is the agent handling financial distress conversations correctly? Is it reading churn intent accurately? Is the pattern holding, or has something drifted?
Sergey frames it as a control problem. “You don’t want your users to know about issues before you do. Proactively detecting problems is the goal. You shouldn’t need your customers to report it.”
The Gainsight renewal agent, part of Gainsight’s agentic offering, Atlas, is designed to scale CS coverage into segments where human-led outreach can’t reach. That only works if the agent is actually good at the job, not just completing the task. An agent that handles most conversations competently but badly misreads the distressed customer call creates as many problems as it solves. The eval system is what makes the difference between an agent that performs in a controlled test environment and one that holds up when real customers, with real problems and real business pressures, pick up the phone.
The harder thing this work forces you to accept is that “good enough” is a moving target. Every iteration surfaces something new. The failure modes don’t have an end state. The feedback loop is the work, not a phase of it.
About This Article

This article draws from detailed conversations with Skye Maddox, CSM at Envoy (contracted to Gainsight’s Atlas team for AI agent evaluation work), and Sergey Kondratiuk, Principal Engineer at Gainsight, on the human-AI collaboration behind Gainsight’s renewal agent eval system.